
El aprendizaje automático es un campo vasto y dinámico, y dentro de él, el clustering o agrupamiento juega un papel fundamental. Los modelos de clustering son herramientas poderosas diseñadas para descubrir estructuras ocultas en los datos, organizándolos en grupos o "clusters" basados en sus similitudes intrínsecas. Sin embargo, la verdadera utilidad y éxito de estos modelos no se mide simplemente por su capacidad de dividir un conjunto de datos, sino por la calidad intrínseca de esa separación. Como bien se ha señalado, "Clustering models in machine learning must be assessed by how well they separate data into meaningful groups with distinctive characteristics." Esta afirmación encapsula la esencia de la evaluación de cualquier algoritmo de agrupamiento: ir más allá de la mera fragmentación de datos para buscar una segmentación que aporte valor, que sea interpretable y que refleje patrones subyacentes significativos.
¿Por qué es crucial esta evaluación?
A diferencia de los modelos de clasificación, donde tenemos etiquetas de verdad fundamental para medir la precisión, los modelos de clustering son de aprendizaje no supervisado. Esto significa que operan sin una guía preexistente sobre cómo deberían ser los grupos. Por lo tanto, determinar si los grupos formados son "buenos" o "malos" requiere un enfoque más matizado. Una mala evaluación puede llevar a conclusiones erróneas, decisiones de negocio equivocadas o la aplicación ineficaz de recursos. Evaluar "cuán bien" se separan los datos es, en esencia, validar la hipótesis de que existe una estructura natural y significativa dentro del conjunto de datos.
Componentes clave de una evaluación efectiva:
La afirmación original destaca dos aspectos fundamentales: la creación de "grupos significativos" y la presencia de "características distintivas".
1. Separación en grupos significativos:
- Cohesión interna (Intra-cluster similarity): Los elementos dentro de un mismo cluster deben ser lo más similares posible entre sí. Esto garantiza que cada grupo represente una entidad coherente y homogénea. Si los elementos de un cluster son muy disímiles, el grupo carece de un significado claro y su utilidad se reduce.
- Separación externa (Inter-cluster separation): Los diferentes clusters deben ser lo más disímiles posible entre sí. Esto asegura que los grupos son verdaderamente distintos y no simplemente variaciones del mismo concepto. Una buena separación evita la superposición de conceptos y facilita la interpretación de cada grupo como una categoría única.
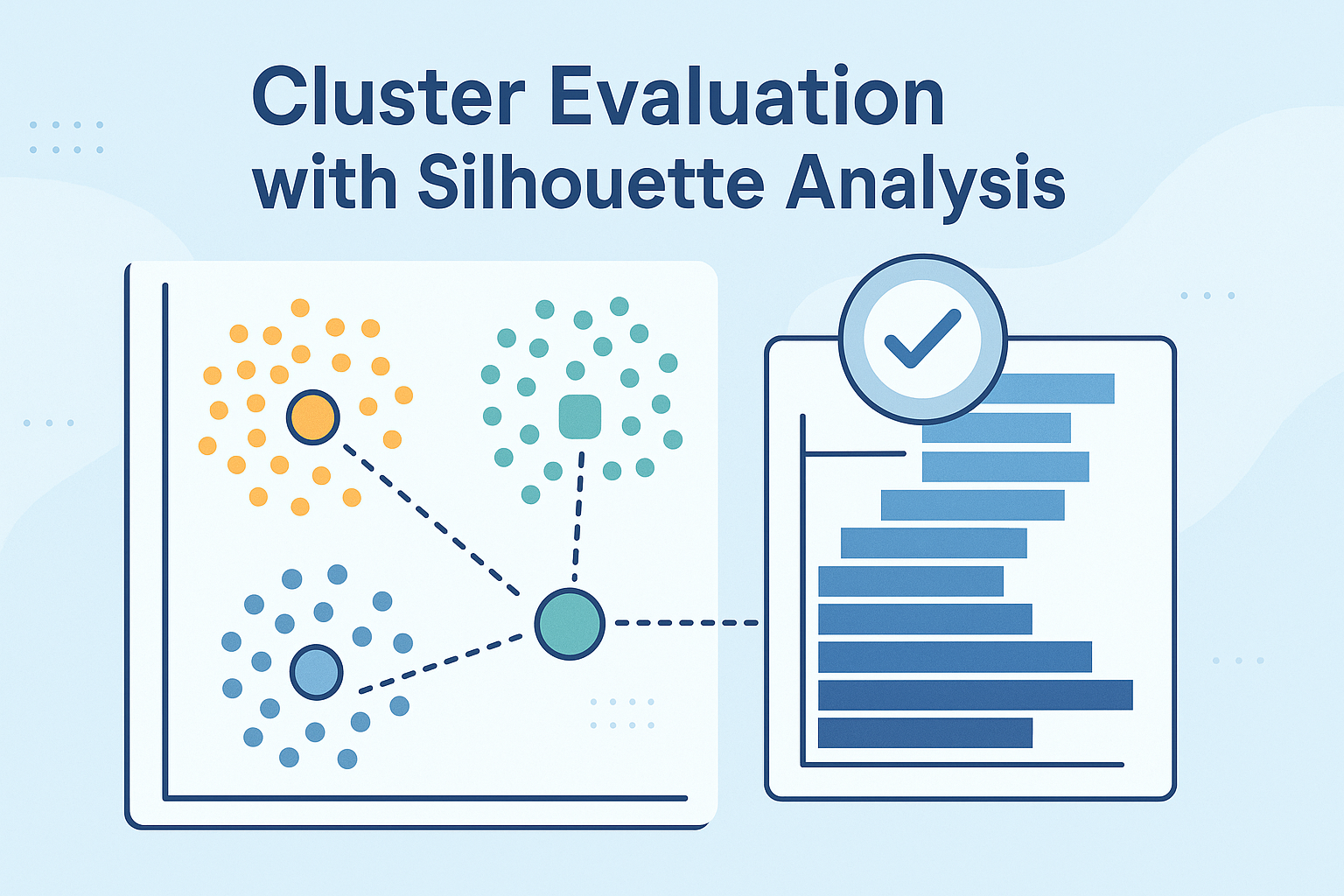
- Número óptimo de clusters: A menudo, el desafío no es solo formar grupos, sino determinar cuántos grupos son los más adecuados. Un número insuficiente puede ocultar patrones importantes, mientras que un exceso puede fragmentar los datos de manera artificial, creando grupos triviales o irrelevantes. Métodos como el "método del codo" o el "coeficiente de silueta" buscan abordar este problema.
2. Características distintivas:
Una vez que los datos están separados, es vital que los grupos resultantes posean características que los hagan únicos y diferenciables. No basta con que los clusters estén separados matemáticamente; deben ser "interpretables" por un experto del dominio.
- Interpretación: ¿Podemos describir por qué un grupo es diferente de otro? Por ejemplo, en un estudio de clientes, ¿un cluster representa a "jóvenes tecnológicos" y otro a "adultos conservadores"? Si la respuesta es sí, entonces las características (edad, hábitos de compra, uso de tecnología) son distintivas y los grupos son significativos.
- Aplicabilidad: ¿La distinción entre clusters es útil para el problema en cuestión? Un cluster puede tener características distintivas, pero si estas no son relevantes para el objetivo (por ejemplo, segmentación de mercado, detección de anomalías), su utilidad práctica es limitada.
- Estabilidad: ¿Los clusters se mantienen estables si se perturba ligeramente el conjunto de datos o se utilizan diferentes semillas iniciales (en algoritmos estocásticos como K-Means)? Un modelo robusto producirá agrupamientos consistentes.
Métodos y Métricas de Evaluación:
Para cuantificar "cuán bien" los modelos de clustering cumplen con estos criterios, se utilizan diversas métricas, clasificadas generalmente en:
- Métricas intrínsecas (internas): Evalúan la bondad de los clusters basándose únicamente en la estructura de los datos y el agrupamiento resultante, sin información externa.
- Coeficiente de Silueta: Mide cuán similar es un objeto a su propio cluster (cohesión) en comparación con otros clusters (separación). Los valores van de -1 a 1, donde 1 indica clusters bien separados, 0 indica solapamiento y -1 indica que el objeto ha sido asignado al cluster incorrecto. Es una de las métricas más populares y directas para evaluar la calidad individual de los puntos y, por ende, del agrupamiento global.
- Índice Davies-Bouldin: Evalúa la relación entre la dispersión dentro de los clusters y la separación entre clusters. Un valor más bajo indica un mejor agrupamiento.
- Índice Calinski-Harabasz: También conocido como la relación de varianza, mide la relación entre la varianza entre clusters y la varianza dentro de los clusters. Un valor más alto generalmente indica clusters más densos y mejor separados.
- Métricas extrínsecas (externas): Requieren el conocimiento de la verdad fundamental (ground truth) o etiquetas preexistentes para comparar el agrupamiento con una partición conocida. Aunque no siempre disponibles en clustering (que es no supervisado), son útiles para benchmarking o cuando se tienen subconjuntos etiquetados.
- Índice de Rand Ajustado (ARI): Mide la similitud entre dos agrupamientos (el predicho y el real), ajustando por el azar.
- Información Mutua Normalizada (NMI): Mide la cantidad de información compartida entre el agrupamiento y las etiquetas reales.
Desafíos y consideraciones:
La evaluación de modelos de clustering no es una tarea sencilla y presenta varios desafíos:
- Subjetividad de "significativo": Lo que es significativo para un dominio puede no serlo para otro. La interpretabilidad a menudo requiere la validación de expertos en la materia.
- Dimensionalidad: En datos de alta dimensionalidad, la noción de distancia se vuelve menos intuitiva, lo que puede afectar la formación y evaluación de los clusters.
- Forma de los clusters: Muchos algoritmos asumen formas de cluster específicas (por ejemplo, esféricas en K-Means). Las métricas pueden no ser justas para clusters de formas irregulares.
- Ruido y valores atípicos: Los datos ruidosos pueden distorsionar la formación de clusters y la evaluación.
Conclusión:
En última instancia, la evaluación de los modelos de clustering trasciende la mera aplicación de un algoritmo. Se trata de un proceso iterativo y reflexivo que busca validar la utilidad y la calidad de los patrones descubiertos. La frase "Clustering models in machine learning must be assessed by how well they separate data into meaningful groups with distinctive characteristics" no es solo una directriz; es un principio fundamental que nos recuerda que el verdadero valor del clustering reside en su capacidad para transformar datos crudos en información interpretable y accionable. Al enfocarnos en la cohesión interna, la separación externa, la interpretabilidad de las características distintivas y el uso de métricas apropiadas, podemos asegurar que nuestros modelos de agrupamiento no solo dividan los datos, sino que también revelen perspicacias valiosas que impulsen el conocimiento y la innovación.