
En el desarrollo de aplicaciones de Inteligencia Artificial (IA), una evaluación exhaustiva es fundamental para garantizar que los sistemas ofrezcan respuestas precisas, fiables y contextualmente apropiadas. Microsoft ha anunciado mejoras significativas en las bibliotecas Microsoft.Extensions.AI.Evaluation, introduciendo nuevos evaluadores que amplían las capacidades de evaluación en dos áreas clave: la valoración de la calidad de los agentes de IA y las métricas de Procesamiento de Lenguaje Natural (PLN).
Evaluadores de Calidad de Agentes
El paquete Microsoft.Extensions.AI.Evaluation.Quality incorpora ahora tres nuevos evaluadores diseñados específicamente para medir el rendimiento de los agentes de IA en escenarios conversacionales que implican el uso de herramientas:
- IntentResolutionEvaluator: Mide la eficacia con la que un agente comprende y aborda la intención del usuario. Es crucial para asegurar que el agente no solo capta lo que el usuario pide, sino que también actúa de forma coherente con esa intención. Un buen desempeño aquí indica una alta comprensión contextual por parte del agente.
- TaskAdherenceEvaluator: Evalúa si un agente se mantiene enfocado en la tarea asignada a lo largo de una conversación. Esto es vital para evitar desviaciones y garantizar que el agente sigue un flujo lógico y productivo, especialmente en interacciones complejas donde el usuario podría intentar desviar la conversación.
- ToolCallAccuracyEvaluator: Evalúa la precisión y la idoneidad de las llamadas a herramientas realizadas por el agente. En escenarios donde los agentes interactúan con sistemas externos a través de herramientas, la correcta invocación y uso de estas herramientas es un indicador directo de su funcionalidad y fiabilidad.
Evaluadores de PLN (Procesamiento de Lenguaje Natural)
También se ha introducido un nuevo paquete, Microsoft.Extensions.AI.Evaluation.NLP, que contiene evaluadores que implementan algoritmos comunes de PLN para medir la similitud textual:
- BLEUEvaluator: Implementa la métrica BLEU (Bilingual Evaluation Understudy), ampliamente utilizada para medir la similitud entre un texto generado y uno o varios textos de referencia, comúnmente en tareas de traducción automática.
- GLEUEvaluator: Proporciona la métrica GLEU (Google BLEU), una variante optimizada para la evaluación a nivel de oración. Es particularmente útil cuando la granularidad de la evaluación es más fina, permitiendo un análisis más detallado de la calidad de la respuesta.
- F1Evaluator: Calcula las puntuaciones F1 para tareas de similitud de texto y recuperación de información. La puntuación F1 es una medida armónica de precisión y exhaustividad, lo que la hace ideal para evaluar el equilibrio entre la relevancia de las respuestas y la cobertura de la información.
A diferencia de otros evaluadores en las bibliotecas Microsoft.Extensions.AI.Evaluation, los evaluadores de PLN **no requieren un modelo de IA** para realizar las evaluaciones. En su lugar, utilizan técnicas tradicionales de PLN, como la tokenización de texto y el análisis de n-gramas, para calcular puntuaciones de similitud. Esto los hace herramientas flexibles y eficientes para tareas específicas de comparación de texto.
Estos nuevos evaluadores complementan los evaluadores existentes centrados en la calidad y la seguridad, ofreciendo un conjunto robusto de herramientas de evaluación para las aplicaciones de IA en .NET, incluyendo la posibilidad de crear evaluadores personalizados y específicos de dominio.
Configuración de la Conexión LLM
Los evaluadores de calidad de agentes requieren un modelo de lenguaje grande (LLM) para realizar la evaluación. El ejemplo de código demuestra cómo crear un IChatClient que se conecta a un modelo desplegado en Azure OpenAI. Es fundamental configurar correctamente el entorno:
- Se recomienda usar modelos de la serie GPT-4o o GPT-4.1, ya que los prompts de evaluación de
Microsoft.Extensions.AI.Evaluation.Qualityhan sido ajustados y probados con ellos. Aunque se pueden usar otros modelos, su rendimiento podría variar, siendo potencialmente inferior en modelos más pequeños o locales. - Se deben establecer variables de entorno para el endpoint de Azure OpenAI y el nombre de despliegue del modelo.
- La autenticación se realiza mediante DefaultAzureCredential, lo que permite iniciar sesión con herramientas de desarrollo como Visual Studio o Azure CLI.
Configuración de un Proyecto de Prueba
Para probar los nuevos evaluadores, se puede crear un nuevo proyecto de prueba MSTest utilizando Visual Studio, Visual Studio Code con C# Dev Kit, o la CLI de .NET. Una vez creado, es necesario añadir los paquetes NuGet esenciales:
dotnet add package Azure.AI.OpenAI
dotnet add package Azure.Identity
dotnet add package Microsoft.Extensions.AI.Evaluation
dotnet add package Microsoft.Extensions.AI.Evaluation.Quality
dotnet add package Microsoft.Extensions.AI.Evaluation.NLP --prerelease
dotnet add package Microsoft.Extensions.AI.Evaluation.Reporting
dotnet add package Microsoft.Extensions.AI.OpenAI --prerelease
Ejemplo de Código y Funcionamiento
El código de ejemplo (en Test1.cs) ilustra cómo ejecutar los evaluadores de calidad de agentes y de PLN a través de dos pruebas unitarias separadas:
Evaluación de Calidad de Agentes (EvaluateAgentQuality)
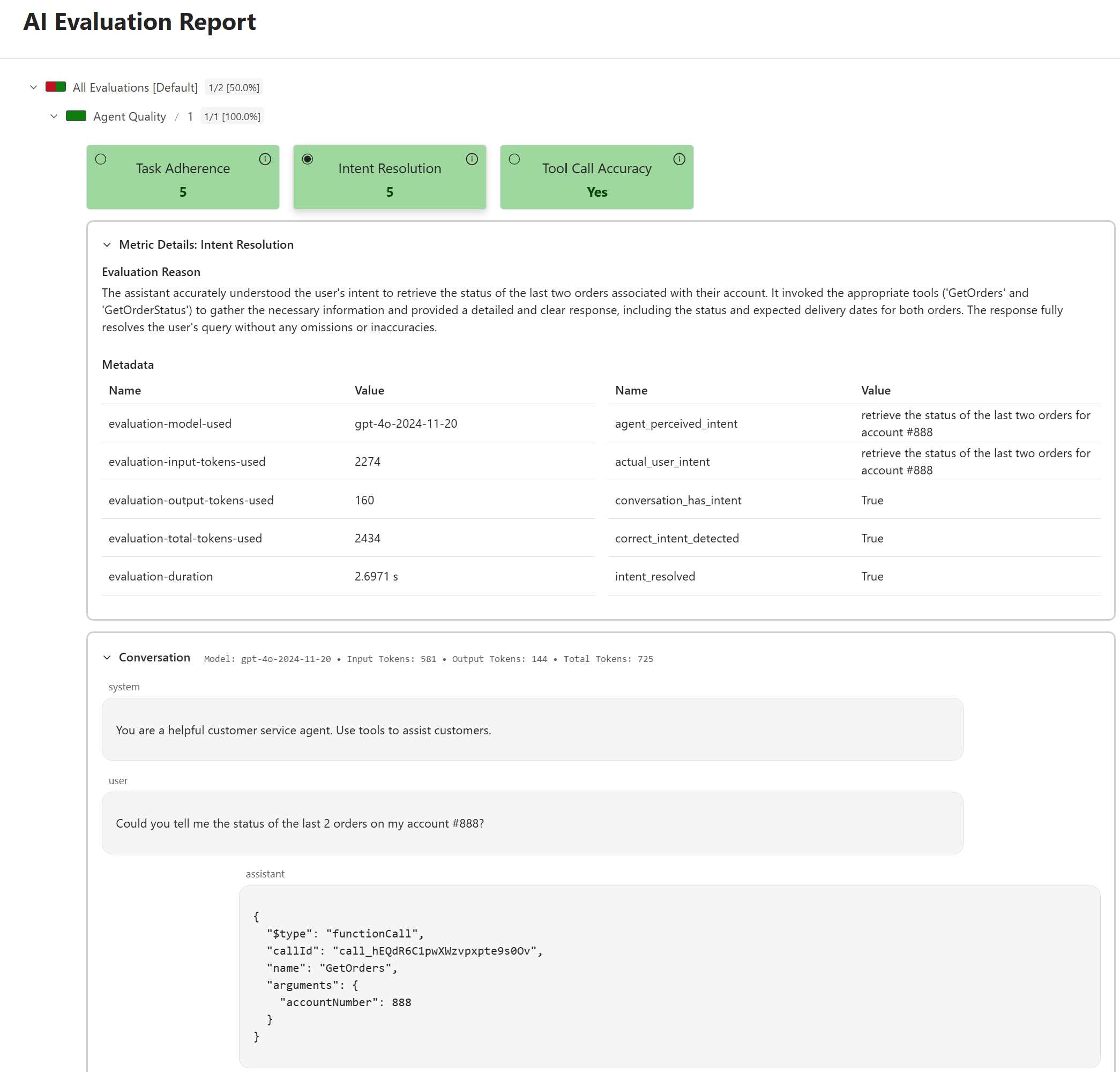
Esta prueba simula un agente de servicio al cliente que utiliza herramientas (GetOrders y GetOrderStatus) para responder a un usuario. Se configuran los evaluadores (ToolCallAccuracyEvaluator, TaskAdherenceEvaluator, IntentResolutionEvaluator) y se les proporciona las definiciones de las herramientas. El ScenarioRun ejecuta la evaluación contra la respuesta del agente y los resultados se persisten en disco. Se verifica que la métrica de Resolución de Intención (IntentResolutionMetricName) no indique un fallo.
La configuración para esta prueba incluye la creación de un IChatClient conectado a Azure OpenAI, habilitando el soporte para invocación de funciones (herramientas) y configurando el almacenamiento de resultados en ./eval-results con caché de respuestas habilitada. La caché es útil para evitar recomputaciones innecesarias de respuestas de LLM si las entradas permanecen inalteradas.
Evaluación de Métricas de PLN (EvaluateNLPMetrics)
Esta prueba demuestra el uso de los evaluadores de PLN (BLEUEvaluator, GLEUEvaluator y F1Evaluator) para medir la similitud de texto. Se compara una respuesta de modelo de ejemplo con una lista de respuestas de referencia «ideales». Los evaluadores de PLN, al no requerir un LLM, se configuran de manera más sencilla. La prueba verifica que la métrica F1 (F1MetricName) no indique un fallo. Al igual que con los evaluadores de agentes, los resultados se guardan en el mismo directorio ./eval-results.
La configuración de esta prueba es más simple, ya que no necesita un IChatClient, solo el storageRootPath y los evaluadores de PLN.
Ejecución de Pruebas y Generación de Informes
Tras ejecutar las pruebas unitarias (a través de Visual Studio, VS Code o dotnet test), se puede generar un informe HTML detallado para ambos escenarios («Agent Quality» y «NLP») usando la herramienta dotnet aieval.
Primero, instala la herramienta localmente en tu proyecto:
dotnet tool install Microsoft.Extensions.AI.Evaluation.Console --create-manifest-if-needed
Luego, genera y abre el informe:
dotnet aieval report -p <ruta a la carpeta 'eval-results' bajo el directorio de salida de build del proyecto> -o .\report.html --open
El flag --open abre automáticamente el informe generado en tu navegador predeterminado, permitiendo una exploración interactiva de los resultados de evaluación, como se muestra en la captura de pantalla donde se detallan las métricas de «Intent Resolution».
Más Información y Comentarios
Para ejemplos más completos, buenas prácticas y patrones de uso de las bibliotecas Microsoft.Extensions.AI.Evaluation, puedes explorar los API Usage Examples en el repositorio dotnet/ai-samples. La documentación y tutoriales están disponibles en The Microsoft.Extensions.AI.Evaluation libraries.
Se anima a la comunidad a probar estos evaluadores y compartir sus comentarios y sugerencias en GitHub, lo que contribuye a la mejora continua de estas herramientas esenciales para el desarrollo de IA en .NET.
¡Feliz evaluación!