
El mundo del desarrollo de aplicaciones está en constante evolución, y la integración de la Inteligencia Artificial (IA) ofrece una de las vías más emocionantes para revitalizar y potenciar las aplicaciones existentes. Tradicionalmente, las interacciones se han limitado a entradas de texto o gestos táctiles. Sin embargo, gracias a los avances en IA y herramientas como .NET MAUI, ahora es más sencillo que nunca expandir estas capacidades para incluir la voz y la visión, lo que resulta particularmente beneficioso en dispositivos móviles, donde la entrada de voz puede ser más natural e intuitiva.
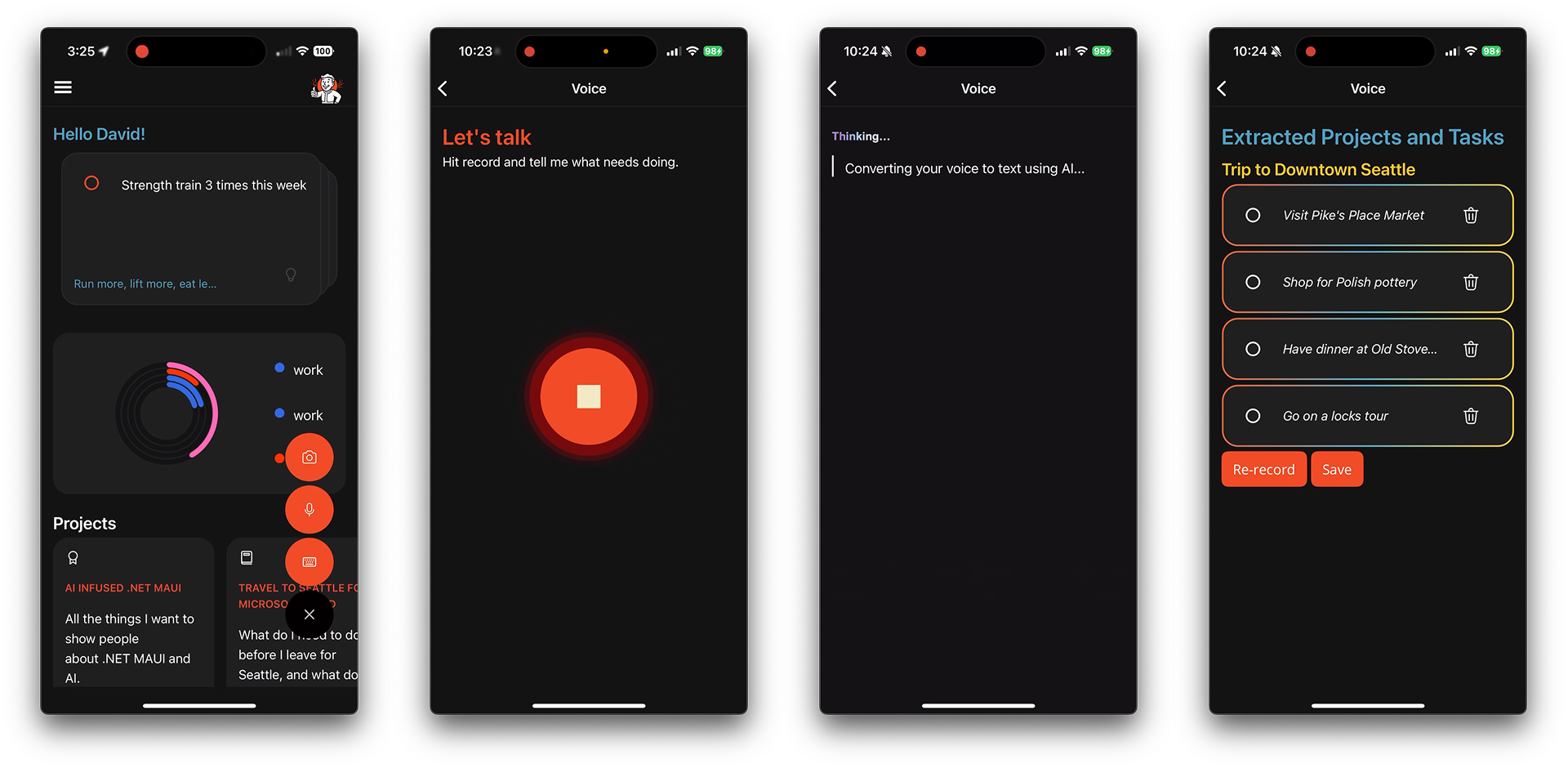
En Microsoft Build 2025, se presentó una demostración impactante: la aplicación de ejemplo «to do» de .NET MAUI, que inicialmente dependía de la entrada de texto, fue mejorada para admitir interacción por voz y visión cuando estas capacidades eran detectadas. Este artículo detalla cómo .NET MAUI, junto con su robusto ecosistema de plugins, facilita esta implementación de manera fluida y con una única base de código para todas las plataformas, comenzando por la voz.
Conversando con la Aplicación: La Revolución de los LLM
La idea de hablar con una aplicación no es novedosa; asistentes como Siri, Alexa o Cortana nos han acompañado durante años. La clave ha estado siempre en conocer los comandos y palabras clave específicos que estos sistemas podían comprender y ejecutar, como «iniciar un temporizador» o «bajar el volumen».
La verdadera revolución llega con los modelos de lenguaje grandes (LLM). Estas potentes herramientas pueden ahora tomar nuestras «divagaciones» no estructuradas y darles sentido, transformándolas en el formato estructurado que nuestras aplicaciones necesitan. Esto abre un abanico de posibilidades para interacciones más naturales y eficientes.
Paso 1: Escuchar el Audio
Para habilitar la entrada de voz, el primer paso es integrar el paquete NuGet Plugin.Maui.Audio. Este plugin es fundamental, ya que nos permite solicitar los permisos necesarios para acceder al micrófono del dispositivo y comenzar a capturar un flujo de audio. Además de la grabación, el plugin también soporta la reproducción de audio, lo que lo convierte en una solución versátil.
La configuración inicial se realiza en MauiProgram.cs. Aquí, se especifican las opciones de grabación, especialmente importantes para plataformas como iOS o Mac Catalyst, donde se definen categorías y modos de sesión de audio para asegurar una integración adecuada con el sistema operativo. También se registra el servicio IAudioService del plugin en el contenedor de servicios de la aplicación, haciendo que la funcionalidad de audio esté disponible en toda la aplicación.
Es vital revisar la documentación del plugin para cualquier configuración adicional específica de la plataforma.
Con el plugin configurado, la aplicación está lista para capturar audio. En la `VoicePage` de la aplicación de ejemplo, el usuario interactúa mediante un botón de micrófono: un toque inicia la grabación, y otro toque la detiene. El código detrás de esta interacción, implementado con un RelayCommand, maneja de forma asíncrona la solicitud y verificación de permisos del micrófono, esencial para la privacidad del usuario. Si los permisos son concedidos, se inicializa el grabador de audio, se comienza a grabar y se actualiza el estado de la UI (por ejemplo, cambiando el texto del botón de «Grabar» a «Detener»). Al detener la grabación, el flujo de audio capturado se guarda y se prepara para el siguiente paso: la transcripción.
Paso 2: Transcribir el Discurso
Una vez que se tiene el flujo de audio, el siguiente paso es transcribirlo a texto. La aplicación de ejemplo utiliza Microsoft.Extensions.AI en conjunto con OpenAI para esta tarea, aprovechando el modelo whisper-1, un modelo de vanguardia diseñado específicamente para la conversión de voz a texto de alta precisión.
El proceso implica guardar el flujo de audio capturado en un archivo temporal (por ejemplo, un archivo `.wav` con un nombre único basado en la marca de tiempo) dentro del directorio de caché del sistema de archivos. Este archivo se pasa luego al servicio de transcripción.
La implementación del servicio de transcripción, como WhisperTranscriptionService, muestra cómo se utiliza una clave API de OpenAI para autenticar las solicitudes. El archivo de audio se lee como un flujo y se envía al cliente de audio de OpenAI para su procesamiento. La respuesta de OpenAI contiene el texto transcrito, que luego se utiliza para el análisis posterior.
La flexibilidad es una característica clave: Microsoft.Extensions.AI permite cambiar fácilmente entre diferentes servicios de IA basados en la nube o incluso soluciones en el dispositivo. Por ejemplo, el .NET MAUI Community Toolkit ofrece SpeechToText para el reconocimiento de voz local, y también se pueden integrar LLM locales mediante ONNX Runtime, ofreciendo opciones para diversos escenarios y requisitos de rendimiento/privacidad.
Paso 3: Dar Sentido y Estructura
Con el texto transcrito en mano, el desafío ahora es transformar esa «rambling» no estructurada en datos significativos y estructurados que la aplicación pueda usar. Aquí es donde los LLM demuestran su poder, actuando como un intérprete inteligente. El método ExtractTasksAsync es el encargado de esta lógica.
Se construye un «prompt» cuidadosamente diseñado para guiar al modelo de IA (en este caso, gpt-4o-mini) sobre cómo procesar el texto. Este prompt incluye instrucciones claras:
- Definir «tareas» como elementos accionables (ej., «Comprar víveres»).
- Definir «proyectos» como tareas más grandes que pueden contener múltiples subtareas (ej., «Planificar fiesta de cumpleaños»).
- Especificar que las tareas deben agruparse bajo un único proyecto.
- Establecer un formato de fecha estándar (YYYY-MM-DD) para cualquier fecha mencionada.
El servicio _chatClientService, una instancia de IChatClient de Microsoft.Extensions.AI, envía este prompt. La magia ocurre con el método GetResponseAsync, que no solo procesa el prompt sino que también espera una respuesta fuertemente tipada (ProjectsJson en este caso). El LLM devuelve una estructura JSON que contiene una lista de proyectos con sus respectivas tareas, lista para ser utilizada por la aplicación.
Co-creación: Mejorando la Experiencia del Usuario con IA
Convertir la voz en datos estructurados es un gran avance, pero el artículo subraya un punto crucial: la «co-creación». No basta con insertar los resultados de la IA directamente en la base de datos. Para una experiencia verdaderamente satisfactoria, es fundamental un paso de aprobación por parte del usuario. Podría haber un error de transcripción, una tarea malinterpretada o incluso una omisión.
Por ello, se recomienda presentar al usuario las tareas y proyectos como recomendaciones, dándoles la opción de revisarlos, ajustarlos y finalmente aceptarlos o descartarlos. Esta interacción es similar a la que encontramos en herramientas como Copilot, donde el usuario mantiene el control y puede iterar sobre las sugerencias de la IA. Este enfoque mejora la confianza del usuario y la precisión final de los datos.
Para aquellos interesados en diseñar experiencias de IA excepcionales, Microsoft recomienda consultar el HAX Toolkit y los Principios de IA de Microsoft, que ofrecen guías valiosas para implementar IA de manera responsable y efectiva.
Conclusión
Este artículo ha desglosado cómo enriquecer las aplicaciones .NET MAUI con capacidades de IA multimodales, centrándose específicamente en la interacción por voz. Hemos visto cómo:
- Implementar la grabación de audio utilizando
Plugin.Maui.Audio. - Transcribir el habla a texto con
Microsoft.Extensions.AIy el potente modelo Whisper de OpenAI. - Extraer datos estructurados (proyectos y tareas) de entradas de voz no estructuradas utilizando LLM.
Al combinar estas tecnologías, los desarrolladores de .NET MAUI pueden transformar una aplicación tradicional basada en formularios en una interfaz inteligente que entiende y procesa comandos de voz de manera eficiente. La gran ventaja es que todo esto se logra con una única base de código, compatible con todas las plataformas, lo que democratiza el acceso a estas capacidades avanzadas.
En última instancia, la adopción de estas técnicas mejora significativamente la experiencia del usuario, haciendo las aplicaciones más accesibles, intuitivas y potentes, especialmente en entornos móviles donde la voz ofrece una alternativa mucho más cómoda y rápida que la entrada manual de texto.